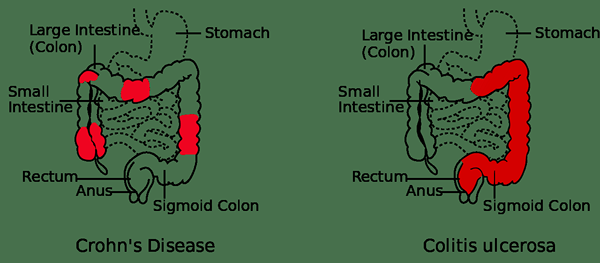
Perbedaan antara kecenderungan sentral dan dispersi

Kecenderungan sentral vs dispersi
Dalam statistik deskriptif dan inferensial, beberapa indeks digunakan untuk menggambarkan kumpulan data yang sesuai dengan kecenderungan pusat, dispersi, dan kemiringannya: tiga sifat paling penting yang menentukan bentuk relatif dari distribusi set data suatu.
Apa kecenderungan sentral?
Kecenderungan sentral mengacu pada dan menempatkan pusat distribusi nilai. Rata -rata, mode, dan median adalah indeks yang paling umum digunakan dalam menggambarkan kecenderungan pusat dari suatu kumpulan data. Jika set data simetris, maka median dan rata -rata set data bertepatan satu sama lain.
Diberikan set data, rata -rata dihitung dengan mengambil jumlah dari semua nilai data dan kemudian membaginya dengan jumlah data. Misalnya, bobot 10 orang (dalam kilogram) diukur menjadi 70, 62, 65, 72, 80, 70, 63, 72, 77 dan 79. Maka berat rata -rata sepuluh orang (dalam kilogram) dapat dihitung sebagai berikut. Jumlah bobot adalah 70 + 62 + 65 + 72 + 80 + 70 + 63 + 72 + 77 + 79 = 710. Rata -rata = (jumlah) / (jumlah data) = 710 /10 = 71 (dalam kilogram). Dipahami bahwa outlier (titik data yang menyimpang dari tren normal) cenderung mempengaruhi rata -rata. Dengan demikian, di hadapan outlier berarti saja tidak akan memberikan gambaran yang benar tentang pusat kumpulan data.
Median adalah titik data yang ditemukan di tengah yang tepat dari set data. Salah satu cara untuk menghitung median adalah dengan memesan titik data dalam urutan naik, dan kemudian menemukan titik data di tengah. Misalnya, jika pernah memesan kumpulan data sebelumnya seperti, 62, 63, 65, 70, 70, 72, 72, 77, 79, 80. Oleh karena itu, (70+72)/2 = 71 berada di tengah. Dari sini, terlihat bahwa median tidak perlu ada di set data. Median tidak terpengaruh oleh keberadaan outlier. Oleh karena itu, median akan berfungsi sebagai ukuran yang lebih baik dari kecenderungan sentral di hadapan outlier.
Mode adalah nilai yang paling sering terjadi dalam set data. Pada contoh sebelumnya, nilai 70 dan 72 keduanya terjadi dua kali dan dengan demikian, keduanya adalah mode. Ini menunjukkan bahwa, dalam beberapa distribusi, ada lebih dari satu nilai modal. Jika hanya ada satu mode, kumpulan data dikatakan unimodal, dalam hal ini, kumpulan data adalah bimodal.
Apa itu dispersi?
Dispersi adalah jumlah penyebaran data tentang pusat distribusi. Kisaran dan standar deviasi adalah ukuran dispersi yang paling umum digunakan.
Kisarannya hanyalah nilai tertinggi dikurangi nilai terendah. Dalam contoh sebelumnya, nilai tertinggi adalah 80 dan nilai terendah adalah 62, jadi kisarannya adalah 80-62 = 18. Tetapi rentang tidak memberikan gambaran yang cukup tentang dispersi.
Untuk menghitung standar deviasi, pertama penyimpangan nilai data dari rata -rata dihitung. Rata -rata kuadrat akar dari penyimpangan disebut standar deviasi. Dalam contoh sebelumnya, penyimpangan masing -masing dari rata -rata adalah (70 - 71) = -1, (62 - 71) = -9, (65 - 71) = -6, (72 - 71) = 1, (80 - 71) = 9, (70 - 71) = -1, (63 - 71) = -8, (72 - 71) = 1, (77 - 71) = 6 dan (79 - 71) = 8. Jumlah kotak penyimpangan adalah (-1)2 + (-9)2 + (-6)2 + 12 + 92 + (-1)2 + (-8)2 + 12 + 62 + 82 = 366. Deviasi standar adalah √ (366/10) = 6.05 (dalam kilogram). Kecuali set data sangat miring, dari sini dapat disimpulkan bahwa sebagian besar data dalam interval 71 ± 6.05, dan memang demikian dalam contoh khusus ini.
|
Apa perbedaan antara kecenderungan sentral dan dispersi? • Kecenderungan sentral mengacu pada dan menempatkan pusat distribusi nilai • Dispersi adalah jumlah penyebaran data tentang pusat set data.
|