Perbedaan antara Big Data dan Hadoop

Perbedaan Utama - Big Data vs Hadoop
Data dikumpulkan secara luas di seluruh dunia. Sejumlah besar data ini disebut data besar atau data besar dan tidak dapat ditangani oleh perangkat penyimpanan biasa. Kerangka Perangkat Lunak Hadoop, yang merupakan kerangka kerja open source oleh Apache Software Foundation, dapat digunakan untuk mengatasi masalah ini. Itu perbedaan utama Antara Big Data dan Hadoop adalah itu Big Data adalah sejumlah besar data kompleks sedangkan Hadoop adalah mekanisme untuk menyimpan data besar secara efektif dan efisien.
ISI
1. Ikhtisar dan Perbedaan Utama
2. Apa itu Big Data
3. Apa itu Hadoop
4. Kesamaan antara Big Data dan Hadoop
5. Perbandingan berdampingan - Big Data vs Hadoop dalam bentuk tabel
6. Ringkasan
Apa itu Big Data?
Data diproduksi setiap hari dan dalam jumlah besar. Penting untuk menyimpan data yang dikumpulkan dan menganalisisnya untuk mendapatkan hasil yang lebih baik. Google, Facebook mengumpulkan sejumlah besar data setiap hari. Mengatur data dan menganalisisnya dapat membawa manfaat bagi organisasi. Di bank, penting untuk menganalisis data untuk memahami informasi pelanggan, transaksi, masalah pelanggan. Menganalisis data ini dan pengembangan solusi akan meningkatkan laba. Ini menunjukkan bahwa data memainkan peran penting bagi suatu organisasi untuk bekerja secara efisien dan efektif. Karena data berkembang pesat, database relasional atau perangkat penyimpanan reguler tidak cukup. Sejumlah besar kumpulan data yang sulit disimpan dan diproses dapat disebut sebagai data besar atau data besar.
Data besar
Big Data memiliki tiga properti. Mereka adalah volume, kecepatan, dan variasi. Pertama, data besar adalah volume data yang besar. Data ini dapat mengambil volume byte giga, byte tera atau bahkan lebih tinggi dari itu. Atribut kedua adalah kecepatan. Itu adalah kecepatan di mana data dihasilkan. Ini adalah properti utama dalam menganalisis perubahan lingkungan dan untuk mendeteksi pesawat terbang. Data harus akurat dan berkelanjutan dalam situasi tersebut. Ini adalah faktor yang cukup besar untuk membuat keputusan real-time. Properti utama lainnya adalah Variety, yang menjelaskan jenis data. Data dapat mengambil format teks, video, audio, gambar, format XML, data sensor, dll.
Apa itu Hadoop?
Ini adalah kerangka kerja open source oleh Apache Software Foundation untuk menyimpan data besar di lingkungan terdistribusi untuk memproses paralel. Ini memiliki penyimpanan distribusi yang efektif dengan mekanisme pemrosesan data. Sistem penyimpanan Hadoop dikenal sebagai Sistem file terdistribusi Hadoop (HDFS). Itu membagi data di antara beberapa mesin. Hadoop mengikuti arsitektur master-slave. Node utama dipanggil Node nama dan budak dipanggil Data-node. Data didistribusikan di antara semua node data.
Algoritma utama yang digunakan untuk memproses data di hadoop disebut peta berkurang. Menggunakan program pengurangan peta, pekerjaan dapat dikirim ke node budak. Bahasa default untuk menulis program pengurangan peta adalah Java, tetapi bahasa lain juga dapat digunakan. Data-node atau node budak akan melakukan tugas analisis dan mengirimkan hasilnya kembali ke master-node/name-node. Master-Node/Name-Node memiliki pelacak pekerjaan untuk menjalankan peta mengurangi pekerjaan pada node budak. Slave-nodes/data-node memiliki pelacak tugas untuk menyelesaikan analisis data dan untuk mengirim hasilnya kembali ke node master.
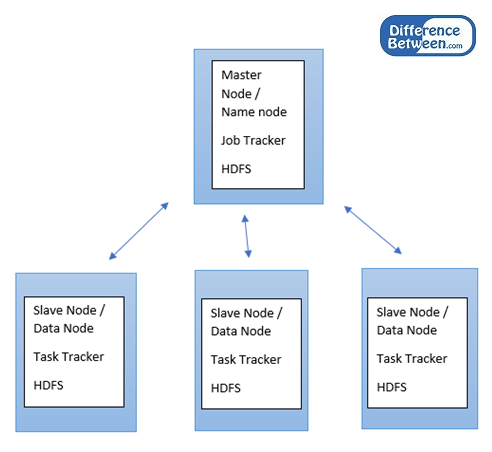
Arsitektur Hadoop
Hadoop memiliki beberapa keuntungan. Ini mengurangi biaya, kompleksitas data dan meningkatkan efisiensi. Mudah untuk menambahkan mesin lain ke cluster Hadoop.
Apa kesamaan antara data besar dan hadoop?
- Data besar dan hadoop terkait dengan sejumlah besar data.
Apa perbedaan antara Big Data dan Hadoop?
Data besar vs hadoop | |
| Big Data adalah kumpulan besar data yang kompleks dan beragam yang sulit disimpan dan dianalisis menggunakan metode penyimpanan tradisional. | Hadoop adalah kerangka kerja perangkat lunak untuk menyimpan dan memproses data besar secara efektif dan efisien. |
| Makna | |
| Big Data tidak memiliki banyak makna. | Hadoop dapat membuat data besar lebih bermakna dan berguna untuk pembelajaran mesin dan analisis statistik. |
| Penyimpanan | |
| Data besar sulit disimpan karena terdiri dari berbagai data seperti data terstruktur dan tidak terstruktur. | Hadoop menggunakan Sistem File Terdistribusi Hadoop (HDFS) yang memungkinkan menyimpan berbagai data. |
| Aksesibilitas | |
| Mengakses Big Data itu sulit. | Hadoop memungkinkan untuk mengakses dan memproses data besar lebih cepat. |
Ringkasan -Besar Data vs Hadoop
Data berkembang pesat. Pemerintah dan organisasi bisnis semuanya mengumpulkan data. Menganalisis data sangat berharga. Satu komputer tidak cukup untuk menyimpan sejumlah besar data. Sejumlah besar data kompleks ini disebut Big Data. Oleh karena itu, data besar dapat didistribusikan di antara beberapa node menggunakan Hadoop. Perbedaan antara Big Data dan Hadoop adalah bahwa Big Data adalah sejumlah besar data kompleks dan Hadoop adalah mekanisme untuk menyimpan data besar secara efektif dan efisien.
Unduh versi PDF dari Big Data vs Hadoop
Anda dapat mengunduh versi PDF artikel ini dan menggunakannya untuk tujuan offline sesuai catatan kutipan. Silakan unduh versi pdf di sini perbedaan antara data besar dan hadoop
Referensi:
1.“Apa itu data besar dan mengapa itu penting."Apa itu Big Data? | Sas Us. Tersedia disini
2.Intinya, tutorial. “Hadoop - Ikhtisar Data Besar.Tutorial Point, 15 Agustus. 2017. Tersedia disini
3.Intinya, tutorial. “Tinjauan Analisis Data Besar.Tutorial Point, 15 Agustus. 2017. Tersedia disini
4.“Apa perbedaan antara Big Data dan Hadoop?”Techopedia.com. Tersedia disini
5.Thippireddybharath. “Big Data dan Hadoop Quick Pendahuluan."YouTube, YouTube, 12 Agustus. 2014. Tersedia disini
Gambar milik:
1.'BigData 2267 × 1146 Trasparent' oleh Camelia.Boban - pekerjaan sendiri, (CC BY -SA 3.0) Via Commons Wikimedia